Event Loop in Node.js
What is Event Loop ?
Event loop, as its name indicates, is a loop that continuously checks for tasks to execute. JavaScript is known to be single-threaded, indicating that codes will run sequentially by nature. However, it's an execution model with poor performance under scenarios such as web services where usually tasks are I/O-bounded(e.g reading files, waiting for db query result), meaning code will spend most of the time waiting for response (blocked) and using none of the CPU power.
The event loop is what allows Node.js to perform non-blocking I/O operations by offloading heavy operations to the system kernel whenever possible, since modern kernels are multi-threaded, whereas the main thread only runs the event loop and other application code.
By introducing the event loop, tasks are categorized and given a defined executing schedule based on priority. Within each loop of the event loop (also known as tick), it will check the queued up tasks according to the defined priority and execute those that are ready for execution.
In short, event loop is responsible to orchestrate and guarantee the execution of tasks that we want to execute in an asynchronous manner.
The implementation of event loop, however, can vary in different runtimes due to different runtime-specific APIs and implementation structure. For instance, Node.js runtime doesn't have Web Apis, such as DOM or the Window, while browser runtime doesn't have file system operations. As well as, event loop is provided through Web API in browser runtime and throug libuv in Node.js runtime.
Desipte the difference, they share a mutual runtime component - V8 engine - that is responsible for executing the JavaScript code. Thus, there's common pattern in the two implementations summarized quite well by Vicky He.
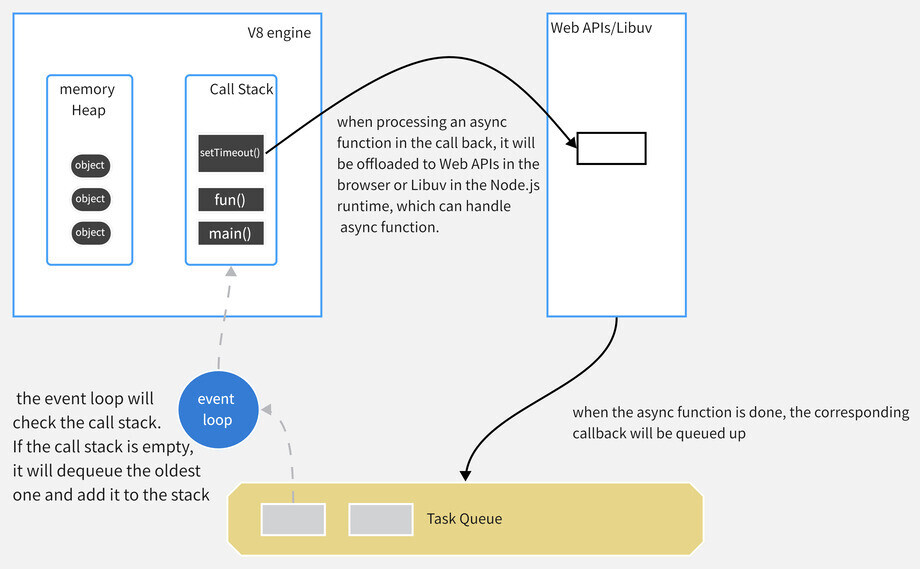
What happens in a single loop ?
There's a change in the execution sequence of tasks in event loop since Node.js v11 to align event loop behaviour with major browsers. Thus, execution result might differ due to differnt node.js version. This note only focus on event loop version after Node.js v11.
Some details can be referred here:
When Node.js starts running, it initiates the event loop and start processing the input script (the script assigned when running Node.js in REPL mode, or indicated in the main field of your package.json).
Tasks are executed in a sequence of phases in each loop. There is a slight discrepancy between the Windows and the Unix/Linux implementation, however, that resulted in differnet numbers of phases. This note will include those that are actually used by Node.js.
Before digging into each phase, it's important to know that task can be categorized into two types : microtask and macrotask. Each includes tasks such as:
macroTask: setTimeout, setInterval, setImmediate, I/OmicroTask: process.nextTick, Promises, queueMicrotask()
Once a macrotask is completed, event loop will check for queued up microTasks and flush them until exhausted before excution another macrotask. And these process repeats throughout the event loop. And Every time the event loop takes a full trip, it's called a tick.
 Event loop phases
Event loop phasesTimer Phase
Despite it's name, a timer does not gurantee the provided callback to be exceuted immediately after the specified threshold a person wants it to be executed has passed.
Timer callbacks will run as early as they can be scheduled after the specified amount of time has passed; however, OS scheduling or the running of other callbacks may delay them.
Take below code as example, as Node.js start processing this code, a timer is spawned on line #11 and callback will be scheduled for execution after 100 ms.
On line #18, someAsyncOperation function is executed and the async operation (fs.readFile) completes after 95 ms, which will then trigger the callback defined with arrow function on line #18 added to the poll-phase queue then runs a blocking while loop for 10 ms interally.
These two operation contributes a total of 105 ms running time, which exceeds the planned 100 ms execution threshold.
Since I/O is handles at the poll phase, this design philosophy leads to a somewhat counter-intuitive concept: the poll phase controls when timers are executed.
// Sample code taken from Node.js official docs guide
const fs = require('fs');
function someAsyncOperation(callback) {
// Assume this takes 95ms to complete
fs.readFile('/path/to/file', callback);
}
const timeoutScheduled = Date.now();
setTimeout(() => {
const delay = Date.now() - timeoutScheduled;
console.log(`${delay}ms have passed since I was scheduled`); // prints `105ms have passed since I was scheduled`
}, 100);
// do someAsyncOperation which takes 95 ms to complete
someAsyncOperation(() => {
const startCallback = Date.now();
// do something that will take 10ms...
while (Date.now() - startCallback < 10) {
// do nothing
}
});
Pending Callback Phase
This phase executes callbacks for some system operations such as types of TCP errors.
Idle/Prepare Phase
This is an internal phase used by Node.js to perform some housekeeping operations such as garbage collection, which won't have direct impact on our application code, nor is it exposed to developers since execution order is not guaranteed in this phase.
It might be possilbe to expose through custom addons, but that is beyond the scope of this note.
Poll Phase
The poll phase has two main functions:
- Calculating how long it should block and poll for I/O, then
- Processing events in the poll queue.
To prevent the poll phase from starving the event loop, libuv also has a hard maximum (system dependent) before it stops polling for more events.
Check Phase
This phase is responsible for executing setImmediate() callbacks.
Close Phase
This phase handles closing of sockets or handles.
Deep Dive
How is timer implemented?
Timer is a crucial concept in Node.js, as any TCP I/O connection creates a timer internally so that we can time out of connections, as well as APIs such as setTimeout use timer internally.
Thus, operations on timer need to be performant and efficient, which leads to an implementation based on linkedlist.
setImmediate v.s setTimeout
setImmediate and setTimeout are similar, but behaviour differs in when they are called. setImmediate is designed to execute a script once the current poll phase completes, and setTimeout schedules a script to be run after a minimum threshold in ms has elapsed.
The order in which the timers are executed will vary depending on the context in which they are called. If both are called from within the main module, then timing will be bound by the performance of the process (which can be impacted by other applications running on the machine).
For example, if we run the following script which is not within an I/O cycle (i.e. the main module), the order in which the two timers are executed is non-deterministic, as it is bound by the performance of the process:
// timeout_vs_immediate.js
setTimeout(() => {
console.log('timeout');
}, 0);
setImmediate(() => {
console.log('immediate');
});
$ node timeout_vs_immediate.js
timeout
immediate
$ node timeout_vs_immediate.js
immediate
timeout
However, if you move the two calls within an I/O cycle, the immediate callback is always executed first:
// timeout_vs_immediate.js
const fs = require('fs');
fs.readFile(__filename, () => {
setTimeout(() => {
console.log('timeout');
}, 0);
setImmediate(() => {
console.log('immediate');
});
});
$ node timeout_vs_immediate.js
> immediate
> timeout
One main advantage to using setImmediate over setTimeout is setImmediate will always be executed before any timers if scheduled within an I/O cycle, independently of how many timers are present.
process.nextTick
An important thing to note that callbacks passed to process.nextTick() is technically not executed as a part of the event loop.
All callbacks passed to process.nextTick() is added to a microtask queue nextTickQueue. Regarless of what phase is the event loop currently in, all callbacks in the queue will be processed after current operation is completed and resolved until the queue is empty before the event loop continues.
An operation is defined as a transition from the underlying C/C++ handler, and handling the JavaScript that needs to be executed.
So why use process.nextTick()? Two main reasons as shown below,
- Allow users to handle errors, cleanup any then unneeded resources, or perhaps try the request again before the event loop continues.
- At times it's necessary to allow a callback to run after the call stack has unwound but before the event loop continues.
In short, use process.nextTick() when a piece of code must be guaranteed to be executed before the next event loop iteration.
cjs vs mjs
Despite the same script, loading it through cjs and mjs results in different result.
const baz = () => console.log('baz');
const foo = () => console.log('foo');
const zoo = () => console.log('zoo');
const start = () => {
console.log('start');
setImmediate(baz);
new Promise((resolve, reject) => {
resolve('bar');
}).then(resolve => {
console.log(resolve);
process.nextTick(zoo);
});
process.nextTick(foo);
};
start();
// execute as index.cjs: start foo bar zoo baz
// execute as index.mjs: start bar foo zoo baz
This is because ES module wraps module loading into an asynchronous operation, and thus the entire script is actually already in the promises microtask queue.
🔗 References
- Node.js Guides
- Gerald Haxhi -- Node.js Internals Series : Part 1 | Part 2 | Part 3 | Part 4
- The confusion with JIT compilation in V8
- How, in general, does Node.js handle 10,000 concurrent requests?
- Bert Belder, IBM -- Morning Keynote: Everything You Need to Know About Node.js Event Loop
- 完整圖解Node.js的Event Loop(事件迴圈)
- The Difference in Event Loop between JavaScript and Node.js